概述
前面介绍过solr构建企业级搜索的基础知识,我们清楚知道solr在构建企业级搜索的优势,可以作为数据库的补充,最为高可用,高并发企业级架构中处理高并发查询的最重要的一环。 这边文章将主要介绍基于solr构建企业级架构,由于企业中的项目多是以分布式架构为基础,因此我们可以将基础的搜索服务独立出来,作为企业级基础项目,为其他项目提供基本的搜索服务。
系统架构
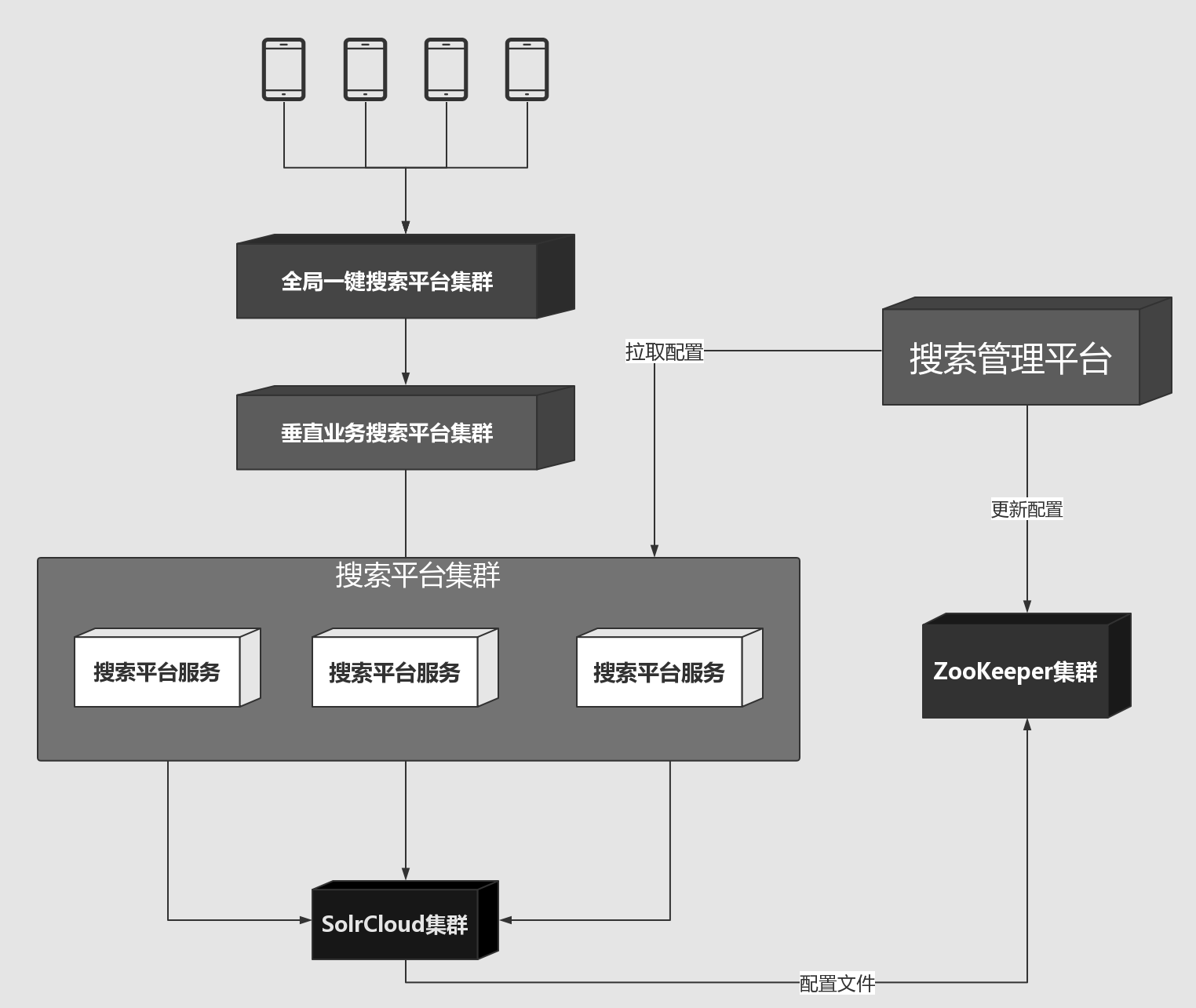
- 搜索管理平台
搜索平台主要是提供统一的搜索规则配置,自动化运营配置,为开发运营提供统一的工具平台 - 搜索平台服务
最为最基础的搜索平台服务,基于分布式rpc框架,对外提供基础的搜索服务,方便其他业务基于此平台深入定制 - 搜素数据服务
为业务提供数据导入导出服务 - 聚合搜索服务
为综合搜索提供一键搜索服务功能
前置条件
在构建分布式企业级搜索时,最好事先搭建好Solr Cloud集群,为以后的平台搭建做准备,详情参考SolrCloud集群配置
搜索管理平台
管理平台主要是管理搜索集合配置、搜索规则、干预规则的平台,平台不负责搜索分发,实际的搜索请求全部由搜索平台服务根据平台提供的配置统一提供服务
技术方案
改平台是一个java web项目,可以基于springboot构建,此项目关键是基于solr cloud的配置体系完成。 以solr构建搜索的核心要点分析,一个构建一个集合所需的配置
- Solr configs
装载solr配置文件,由于solr cloud是将配置文件保存在zookeeper中,因此平台应该提供创建配置文件平台上传到zookeeper的功能 - 配置文件刷新
上传配置文件后需要刷新配置,以是该集合下配置生效 - 搜索规则
solr核心搜索功能需要各种参数配置,可以采用一种集中配置的方法在平台可以随时动态添加修改搜索规则
Solr配置文件
lang/
managed-schema 新版本已经将schema.xml更名以实现自动字段映射的功能
params.json
protwords.txt
solrconfig.xml
stopwords.txt
synonyms.txt
Solr 配置文件为了方便管理最好还是放到版本控制系统中,例如
git
核心接口设计
上传配置文件
/**
* @param biz
* 业务名称 这个业务是为了创建配置名称,一般是以集合collection命名,遵循这个规范即可
* @param file
* 上传文件
* @param request
* @return
*/
@RequestMapping(value = "/conf/upload", method = RequestMethod.POST)
@ResponseBody
public ResponseInfo upload(
@RequestParam(value = "biz", required = true) String biz,
@RequestParam(value = "Filedata", required = true) MultipartFile file,
HttpServletRequest request)
生效配置
生效配置主要包括下面的操作:判断配置是否存在,上传配置文件,创建集合,刷新配置
- 接口定义
/**
* @param shard 分片数
* @param replica 副本数
* @param biz 业务名
* @param request
* @return
*/
@RequestMapping(value = "/conf/effect", method = RequestMethod.GET)
@ResponseBody
public ResponseInfo effect(
@RequestParam(value = "biz", required = true) String biz,
@RequestParam(value = "shard", required = true) String shard,
@RequestParam(value = "replica", required = true) String replica,
HttpServletRequest request)
- 判断配置是否存在
/**
* 判断配置文件是否存在,列出zookeeper中的solr node里面的名称查询
* @param configName 配置文件名称,一般跟集合名称保持一致
*/
private boolean isConfigExist(String configName) throws IOException {
List<String> configList = listChildNode(CONFIGS_ZKNODE);
Set<String> configSet = new HashSet<String>(configList);
return configSet.contains(configName);
}
- 判断是否为文件,单个文件上传
- 上传配置文件
- 判断集合是否存在
/**
* 判断该collection是否已存在
* @param biz 业务名
* @return 存在返回"reload",不存在返回"create",通过返回的属性决定是创建新集合,还是只用刷新集合配置
* @throws IOException
*/
@SuppressWarnings("unchecked")
public String isCollectionExist(String biz){
try {
CollectionAdminRequest.List listRequest = new CollectionAdminRequest.List();
CollectionAdminResponse response = listRequest
.process(cloudSolrClient);
List<String> list = (List<String>) response.getResponse().get(
"collections");
for (int i = 0; i < list.size(); i++) {
if (biz.equals(list.get(i))) {
logger.info("collection: " + biz + "已存在,覆盖reload!");
return "reload";
}
}
} catch (Exception e) {
logger.info("查询collection列表失败", e);
return null;
}
logger.info("collection: " + biz + "不存在,新建collection!");
return "create";
}
- 存在即更新配置
/**
* 生效配置,即生效当前已经上传的集合配置文件
* @param biz 业务名称即是集合名称
* @return
*/
public ResponseInfo reload(String biz) {
cloudSolrClient.setDefaultCollection(biz);
CollectionAdminRequest.Reload reloadCollectionRequest = new CollectionAdminRequest.Reload();
reloadCollectionRequest.setCollectionName(biz);
CollectionAdminResponse response = null;
try {
response = reloadCollectionRequest.process(cloudSolrClient);
if(response.getStatus() != 0) {
throw new Exception();
}
} catch (Exception e) {
logger.info("reload失败", e);
return new ResponseInfo(Result.Status.ERROR, "reload失败", Result.Status.ERROR, "");
}
return new ResponseInfo(Result.Status.SUCCESS, "reload成功", Result.Status.SUCCESS, "");
}
- 不存在直接创建集合
/**
* 生效,创建collection
* @param biz 集合名称
* @param shardNum 分片数量
* @param replicaNum 副本数量
* @return
*/
public ResponseInfo create(String biz, int shardNum, int replicaNum) {
shoudLoadMenuFromZk = true;
CollectionAdminRequest.Create createCollectionRequest = new CollectionAdminRequest.Create();
createCollectionRequest.setCollectionName(biz);
//分片数
createCollectionRequest.setNumShards(shardNum);
//副本数
createCollectionRequest.setReplicationFactor(replicaNum);
//每个solr实例上最多可以放多少个shard
createCollectionRequest.setMaxShardsPerNode(2);
//设置集合的配置名称,即刚刚上传到zookeeper的配置文件
createCollectionRequest.setConfigName(biz);
CollectionAdminResponse response = null;
try {
response = createCollectionRequest.process(cloudSolrClient);
if(response.getStatus() != 0) {
throw new Exception();
}
} catch (Exception e) {
logger.info("创建collection失败",e);
return new ResponseInfo(Result.Status.ERROR, "创建collection失败", Result.Status.ERROR, "");
}
return new ResponseInfo(Result.Status.SUCCESS, "成功创建collection:" + biz, Result.Status.SUCCESS, "");
}
这里实际是调用solr admin api进行集合创建,配置刷新,具体详见使用SolrCloud的Collections API
搜索规则
搜索引擎核心就是搜索,因此如何将solr提供的搜索规则平台是该平台解决问题的关键。前面已经介绍solr可以利用rest api构建query请求实现负责查询,因此平台的搜索规则实际是对不同业务定制的的搜索规则的托管。
核心接口设计
- 规则查询
/**
* @param collectionName 查询的集合名称
*/
@RequestMapping(value = "/query")
@ResponseBody
public QueryInfo query(
@RequestParam(value = "collectionName", required = true) String collectionName)
- 规则创建
/**
* @param collection 集合名称这里配置文件名称一致
* @param type 类型,目前两种:联想与搜索
* @param rule 搜索规则,即是定义的搜索查询条件模板
* @param ssname 搜索描述
* @param params 搜索参数
*/
@RequestMapping(value = "/create",
method = RequestMethod.GET)
@ResponseBody
public ResponseInfo addRule(@RequestParam(value = "collection", required = true) String collection,
@RequestParam(value = "type", required = true) int type,
@RequestParam(value = "rule", required = true) String rule,
@RequestParam(value = "description", required = true) String description,
@RequestParam(value = "params", required = true) String params)
- 规则验证
这里是指用已经定义的搜索条件模板和搜索参数进行模拟搜索,以校验搜索模板的正确性 这里涉及到搜索服务的调用,将在以后讲解
搜索干预
干预是指人工对搜索结果进行控制,进而达到控制搜索结果的目的,用于向用户定向展示内容
搜索平台服务
改服务是基于RPC构建的,旨在提供高效的查询请求,可以分布式部署,以实现高并发请求。 改平台服务基本功能如下:接受来自外部的请求,根据请求collection名称与搜索id进行搜索请求构建,并给予solrJ发送查询请求到SolrCloud,并将查询结果返回
核心查询接口设计
public interface SorlCloudSearch {
/**
* 提供统一的搜索接口,
*
* @param collection 每个业务创建集合时的名称
* @param ruleId 搜索的规则id,数据库存储的规则id
* @param keyword 查询关键字
* @param params 额外的搜索条件,参见ParamNames,以及开发时服务端提供的参数
* @return 搜索结果。
*/
Result search(String collection,int ruleId, String keyword, Map<String, String> params);
/**
* 验证搜索规则时使用
*
* @param core 对应的core名称
* @param rule 搜索规则
* @param params 搜索参数
* @return
*/
Result testSearch(String core, String rule, String params);
/**
* 搜索词联想建议接口
*
* @param bizId 业务接入时分配的id
* @param ruleId 规则ID
* @param keyword 联想关键词
* @param params 其他的参数
* @return 联想结果
*/
Result suggest(String bizId, int ruleId,String keyword, Map<String, String> params);
/**
* 验证搜索联想规则时使用
*
* @param biz 业务Id
* @param rule 搜索规则
* @param params 搜索参数
* @return
*/
Result testSuggest(String biz, String rule,String params);
/**
* 查询满足特定条件的文档,用于干预排序使用
* @param collection 业务
* @param docRule 文档规则
* @return
*/
@Deprecated
Result searchDoc(String collection,String docRule);
/**
* 查询满足特定条件的文档,用于干预排序使用
* @param collection 业务
* @param docRule 文档规则
* @return
*/
Result searchDoc(String collection,String docRule,Map<String,String> otherParams);
/**
* 根据文档id进行查询,不改变原有排序
* @param collection 业务
* @param ids 文档编号
* @param idFiledName id字段名称
* @return
*/
Result searchDocsByIds(String collection, List<String> ids, String idFiledName);
}
规则加载
为了实现快速解析规则,平台服务启动后,应该提前加载规则
- 对于各个collection可能有多个搜索规则
- 根据collection进行分组,每一分组下组合给collection的搜索规则
规则刷新
预加载机制必然导致数据失效性问题,如果 用户中途增加或者修改搜索规则,平台服务需要从数据库中刷新规则,因此这里使用里定时任务,固定时间刷新搜索配置规则
- quartz调度器实现
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd">
<bean id="CloudSolrSearchRuleRefreshJob"
class="org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean">
<property name="targetObject">
<ref bean="your define bean"/>
</property>
<property name="targetMethod">
<value>your define method</value>
</property>
<property name="concurrent" value="false"/>
</bean>
<!-- 添加触发器 -->
<bean id="CloudSolrSearchRefreshCronTrigger" class="org.springframework.scheduling.quartz.CronTriggerBean">
<property name="jobDetail">
<ref bean="CloudSolrSearchRuleRefreshJob"/>
</property>
<property name="cronExpression">
<value>定时时间表达式</value>
</property>
</bean>
<!-- 添加调度器-->
<bean id="cloudSolrSearchRuleSchedulerFactory" class="org.springframework.scheduling.quartz.SchedulerFactoryBean" lazy-init="false">
<property name="triggers">
<list>
<ref bean="CloudSolrSearchRefreshCronTrigger"/>
</list>
</property>
</bean>
</beans>
规则解析
规则解析比较关键,这里主要涉及如何将query语法解析为solrJ可以接受的语法
利用SolrJ发送搜索请求
// Using a ZK Host String
String zkHostString = "zkServerA:2181,zkServerB:2181,zkServerC:2181/solr";
SolrClient solr = new CloudSolrClient.Builder().withZkHost(zkHostString).build();
//构建solr query
SolrQuery query = new SolrQuery();
query.setQuery("sony digital camera");
query.addFilterQuery("cat:electronics","store:amazon.com");
query.setFields("id","price","merchant","cat","store");
query.setStart(0);
query.set("defType", "edismax");
//执行搜索
QueryResponse response = client.query(query);
SolrDocumentList results = response.getResults();
for (int i = 0; i < results.size(); ++i) {
System.out.println(results.get(i));
}
管理平台配置规则
q=_query_:"{!edismax q.op=AND pf=title v=aliasIK:刘德华 mm=100% bf=product(sum(isPrimary,0.01),100)}"&fl=id&sort=score desc,isPrimary desc,id asc
以上实际可以转化为Http请求
curl http://localhost:8983/solr/collection/q=_query_:"{!edismax q.op=AND pf=title v=aliasIK:刘德华 mm=100% bf=product(sum(isPrimary,0.01),100)}"&fl=id&sort=score desc,isPrimary desc,id asc
规则实际配置的是q参数,这个参数可以利用查询解析器构建出各种复杂的查询操作,包括基本的结构化查询参数,标准查询解析器参数
规则转化
现在问题的关键是如何将query参数转化为solrJ可以接收的参数集合
- 通过
&分割查询参数,即可以分割为如下参数,通过源码发现,对addFiledQuery等参数最终是调用add方法添加参数的,因此我们可以以add的方式添加query,如下
SolrQuery query = new SolrQuery();
query.add("fl",id);
query.add("q","_query_:"{!edismax q.op=AND pf=title v=aliasIK:刘德华 mm=100% bf=product(sum(isPrimary,0.01),100)}");
query.add("sort","score desc,isPrimary desc,id asc");
- 参数模板
对于以上搜索模板已经指定了参数参数值,实际上查询模板是不应该事先赋值的,则搜索规则如下:
q=_query_:"{!edismax q.op=AND pf=title v=aliasIK:$<<keyword>> mm=100% bf=product(sum(isPrimary,0.01),100)}"&fl=id&sort=score desc,isPrimary desc,id asc
解析出来的规则模板在进行查询的时候,需要根据用户输入的查询参数进行赋值操作,这里定义$<<>>为标准的参数模板,需要根据参数名进行参数赋值,去掉$<<>>
搜索数据服务
搜索数据服务主要包括以下:
- 业务基于搜索RPC服务定制自己的搜索服务
- 业务根据配置文件批量定时导入数据到solr服务
数据导入服务
为了能够使用solr提供的搜索服务,必须事先导入数据
搜索配置
即是实现上传到zookeeper的索引配置文件
根据搜索配置导入数据
- 利用solrJ提供的api导入文档
SolrClient client = new HttpSolrClient.Builder("http://localhost:8983/solr/collection1").build();
for(int i=0;i<1000;++i) {
SolrInputDocument doc = new SolrInputDocument();
doc.addField("cat", "book");
doc.addField("id", "book-" + i);
doc.addField("name", "The Legend of the Hobbit part " + i);
client.add(doc);
if(i%100==0) client.commit(); // periodically flush
}
client.commit();
搜索数据服务
利用平台服务提供的接口进行二次定制,在改服务下,你可以定制自己的缓存策略,缓存已经查询的结果,避免对平台服务过多的访问,提供搜索效率
该服务实际是指定集合名称,规则id,搜索参数调用平台服务的过程
Map<String, String> params = new HashMap<String, String>();
params.put("keyword", keyword);
//起始页需要转换
params.put("start", param.getPage() * param.getLimit() + "");
params.put("rows", param.getLimit() + "");
//调用搜索平台服务RPC接口
Result result = sorlCloudSearch.search(collectioni, ruleId, keyword,params);
if (result == null || result.getStatus() != ResultStatus.SUCCESS
|| StringUtils.isBlank(result.getJson())) {
LOG.error("query from error, msg=" + (result != null ? result.getErrorMsg() : "")+ ", ruleid=" + ruleId + ", keyword=" + keyword);
}
搜索数据服务采用RPC服务化框架,实现高性能调用,这里就设计到高性能RPC框架例如
Dubbo